Abstract:
We present a flexible model-based approach for the recovery of
parameterized motion from a sequence of 3D meshes without
temporal coherence. Unlike previous model-based approaches using
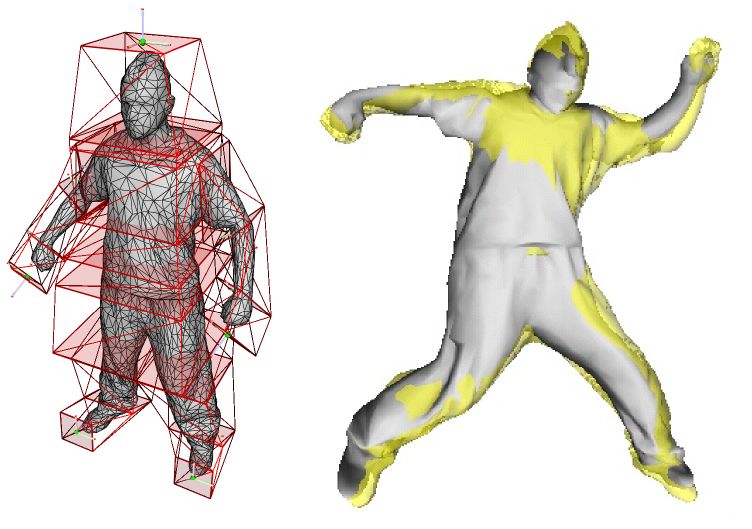
skeletons, we embed the deformation of a reference mesh template
within a low polygonal representation of the mesh, namely the
cage, using Green Coordinates. The advantage is a less
constrained model that more robustly adapts to noisy
observations while still providing structured motion
information, as required by several applications. The cage is
parameterized with a set of 3D features dedicated to the
description of human morphology. This allows to formalize a
novel representation of 3D meshed and articulated characters,
the Oriented Quads Rigging (OQR). To regularize the tracking,
the OQR space is subsequently constrained to plausible poses
using manifold learning. Results are shown for sequences of
meshes, with and without temporal coherence, obtained from
multiple view videos preprocessed by visual hull. Motion
recovery applications are illustrated with a motion transfer
encoding and the extraction of trajectories of anatomical
joints. Validation is performed on the HumanEva II database.
Reference:
Duveau, E., Courtemanche, M., Reveret, L., Boyer, E., "
Cage-based Motion Recovery
using Manifold Learning",
3DIMPVT 2012,,
Zurich, Switzerland, 13-15 oct, 2012.
Paper [
PDF]
Video [
MP4]